Class02¶
CRSP overview¶
Data: security price (and many other trading related data)
Coverage: US stock exchanges
Time period: 1925 - present
Frequency: daily and monthly
Web access¶
Downlaod data from CRSP via WRDS web access.
Dataset: CRSP monthly stock file
Time period: Jan 2011 to Dec 2020
Search the entire database
Variables
shrcd
exchcd
siccd
prc
ret
shrout
cfacpr
permco
cusip
ncusip
Output format
Tab-delimited text
Uncompressed
Date format: YYMMDDn8
Identifiers¶
PERMNO - CRSP permanent security level identifier
- They are permanent and never change
PERMCO - CRSP permanent firm level identifier
- One
PERMCO might have differentPERMNO because a company can issue different securities. For example, Alphabet (Google) has class A and class C shares.- They are permanent and never change
- One
CUSIP - Current 8-digit
CUSIP (security level)- They can be changed. And we can use
NCUSIP to track the change history. - They can be changed. And we can use
NCUSIP - Historical 8-digit
CUSIP (security level)
Note
Stock exchange code¶
1 - NYSE
2 - AMEX
3 - NASDAQ

Share code¶
10 or11 - Common stocks


Stock price¶
PRC - Stock price (unadjusted)
- Some stock prices have negative sign (-)
- Need to take absolute value of price
- Some stock prices have negative sign (-)
$\text{adjusted price} = \frac{\left|prc\right|}{cfacpr}$
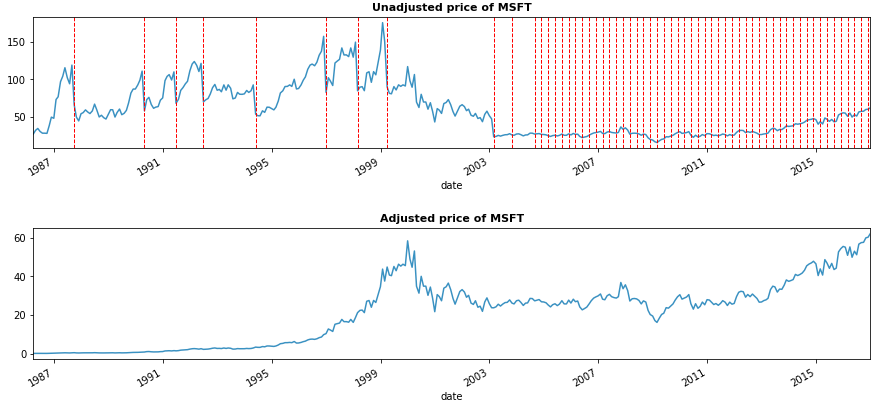
It is important to adjust stock price when evaluating stock performance
Take the example of Microsoft stock price. The vertical red lines indicate corporate actions (e.g. stock splits, dividends). Clearly, the stock return is not correct if unadjusted price is applied.
Note
Market value¶
$\text{market value (millions)} = \frac{|prc| \times shrout}{1000}$
SHROUT - number of shares outstanding (in 1,000 shares)
Volume¶
VOL - Number of traded shares
- 1 share in Daily Stock File
- 100 shares in Monthly Stock File
- 1 share in Daily Stock File
Python¶
Import packages
import pandas as pd
import numpy as np
Import CRSP raw data
Import data from local directory
# Please make sure to change the path to where you save your data file_path = '/Users/ml/Dropbox/teaching/data/crsp_month_raw.txt' crsp_raw = pd.read_csv(file_path, sep='\t', low_memory=False) # View first 5 rows # crsp_raw.head()
Import data from a url
# This url contains sample data from CRSP url = 'https://www.dropbox.com/s/6mk86g97uji2f80/crsp_month_raw.txt?dl=1' crsp_raw = pd.read_csv(url, sep='\t', low_memory=False) # View first 5 rows and first 5 columns crsp_raw.iloc[:5, :5]
PERMNO date SHRCD EXCHCD SICCD 0 10001 20110131 11.0 2.0 4925 1 10001 20110228 11.0 2.0 4925 2 10001 20110331 11.0 2.0 4925 3 10001 20110429 11.0 2.0 4925 4 10001 20110531 11.0 2.0 4925 API reference: pandas.read_csv
Attention
Comments
Any lines starting with
#will be treated as comments and Python will not execute the lines.This is useful when you need to write some comments or notes
Folder path and operating system
Use pathlib library is a better solution if you want to run your codes without problem on different operating systems.
Import the package:
from pathlib import Path
MacOS (Linux)
Forward slash: /folder/file.txt
Windows
Backslash: C:\folder\file.txt
Please use double slashes when typing path:
C:\\folder\\file.txt
Data dimension
# Observations
len(crsp_raw)
870692
# Number of rows and columns (variables)
crsp_raw.shape
(870692, 12)
Data type
# List all variables in the dataset
crsp_raw.columns
Index(['PERMNO', 'date', 'SHRCD', 'EXCHCD', 'SICCD', 'NCUSIP', 'PERMCO',
'CUSIP', 'PRC', 'RET', 'SHROUT', 'CFACPR'],
dtype='object')
# Data type of variables
crsp_raw.dtypes
crsp_raw.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 870692 entries, 0 to 870691
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PERMNO 870692 non-null int64
1 date 870692 non-null int64
2 SHRCD 865287 non-null float64
3 EXCHCD 865287 non-null float64
4 SICCD 865287 non-null object
5 NCUSIP 865287 non-null object
6 PERMCO 870692 non-null int64
7 CUSIP 870692 non-null object
8 PRC 855391 non-null float64
9 RET 860572 non-null object
10 SHROUT 864704 non-null float64
11 CFACPR 864704 non-null float64
dtypes: float64(5), int64(3), object(4)
memory usage: 79.7+ MB
# Rename uppercase to lowercase
# Typing lowercase is easier than uppercase
crsp_raw.columns = crsp_raw.columns.str.lower()
# Convert data type of date to date format
# So that we can apply date functions when manipulating dates
crsp_raw['date'] = pd.to_datetime(crsp_raw['date'], format='%Y%m%d')
# Convert data type of ret to numerical value
# Stock return should be numerical values rather than string
# For example,
# string: '1' + '2' = '12'
# numerical: 1 + 2 = 3
crsp_raw['ret'] = pd.to_numeric(crsp_raw['ret'], errors='coerce')
# Convert siccd to numerical value
crsp_raw['siccd'] = pd.to_numeric(crsp_raw['siccd'], errors='coerce')
crsp_raw.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 870692 entries, 0 to 870691
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 permno 870692 non-null int64
1 date 870692 non-null datetime64[ns]
2 shrcd 865287 non-null float64
3 exchcd 865287 non-null float64
4 siccd 865153 non-null float64
5 ncusip 865287 non-null object
6 permco 870692 non-null int64
7 cusip 870692 non-null object
8 prc 855391 non-null float64
9 ret 849541 non-null float64
10 shrout 864704 non-null float64
11 cfacpr 864704 non-null float64
dtypes: datetime64[ns](1), float64(7), int64(2), object(2)
memory usage: 79.7+ MB
Stock exchanges and common shares
crsp = crsp_raw.copy()
# Keep NYSE/AMEX/NASDAQ
crsp = crsp[crsp['exchcd'].isin([1, 2, 3])]
# Keep common shares
crsp = crsp[crsp['shrcd'].isin([10, 11])]
# Convert shrcd and exchcd to int
crsp[['exchcd', 'shrcd']] = crsp[['exchcd', 'shrcd']].astype(int)
len(crsp)
444358
Drop duplicates It is a good practice to check if there are duplicated observations.
crsp = crsp.drop_duplicates(['permno', 'date'])
len(crsp)
444358
API reference: pandas.dataframe.drop_duplicates
Tip
Categorical data is a good way to reduce the memory usage especially when the data eats up too much your computer memory.
temp = crsp.copy()
# Convert shrcd and exchcd to category
temp[['exchcd', 'shrcd']] = temp[['exchcd', 'shrcd']].astype('category')
temp.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 444358 entries, 0 to 870691
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 permno 444358 non-null int64
1 date 444358 non-null datetime64[ns]
2 shrcd 444358 non-null category
3 exchcd 444358 non-null category
4 siccd 444256 non-null float64
5 ncusip 444358 non-null object
6 permco 444358 non-null int64
7 cusip 444358 non-null object
8 prc 441959 non-null float64
9 ret 439721 non-null float64
10 shrout 444036 non-null float64
11 cfacpr 444036 non-null float64
dtypes: category(2), datetime64[ns](1), float64(5), int64(2), object(2)
memory usage: 38.1+ MB
!!! 38M vs. 80M
Save data
# Remember to change the file path on your machine
outpath = '/Users/ml/Dropbox/teaching/data/crsp_month.txt'
crsp.to_csv(outpath, sep='\t', index=False)
API reference: pandas.dataframe.to_csv
Read clean data
# If you want to import from local
# file_path = '/Users/ml/Dropbox/teaching/data/crsp_month.txt'
# crsp = pd.read_csv(file_path, sep='\t', parse_dates=['date'])
# Import from url
url = 'https://www.dropbox.com/s/0nuxwo3cf7vfcy3/crsp_month.txt?dl=1'
crsp = pd.read_csv(url, sep='\t', parse_dates=['date'])
Generate new variables
# Market value
crsp['price'] = crsp['prc'].abs()
crsp['me'] = (crsp['price']*crsp['shrout']) / 1000
crsp['lnme'] = np.log(crsp['me'])
# Adjusted price
crsp.loc[crsp['cfacpr']>0, 'adjprc'] = crsp['price'] / crsp['cfacpr']
# Holding period returns
crsp['yyyymm'] = crsp['date'].dt.year*100 + crsp['date'].dt.month
# Monthly index
# From 1 to n
# For example, month index will be from 1 to 120 if we have 120 months data
month_idx = crsp.drop_duplicates('yyyymm')[['yyyymm']].copy()
month_idx = month_idx.sort_values('yyyymm', ignore_index=True)
month_idx['midx'] = month_idx.index + 1
crsp = crsp.merge(month_idx, how='left', on='yyyymm')
# Past 6-month returns
crsp['logret'] = np.log(crsp['ret']+1)
crsp = crsp.sort_values(['permno', 'yyyymm'], ignore_index=True)
crsp['hpr'] = (crsp.groupby('permno')['logret']
.rolling(window=6, min_periods=6).sum().reset_index(drop=True))
crsp['hpr'] = np.exp(crsp['hpr']) - 1
crsp['midx_lag'] = crsp.groupby('permno')['midx'].shift(5)
crsp['gap'] = crsp['midx'] - crsp['midx_lag']
temp1 = crsp.query('permno==10028 & 201107<=yyyymm<=201212').copy()
# Replace it by missing if there is month gap.
crsp.loc[crsp['gap']!=5, 'hpr'] = np.nan
temp2 = crsp.query('permno==10028 & 201107<=yyyymm<=201212').copy()
API reference: pandas.dataframe.loc
API reference: pandas.dataframe.query
Attention
Pay attention to month gaps when we use information over multiple periods. Your calculation might be right but data might not be always perfect. Do we have past 6-month data when we compute past 6-month returns?
temp1[['permno', 'yyyymm', 'midx', 'midx_lag', 'gap', 'ret', 'hpr']]
| permno | yyyymm | midx | midx_lag | gap | ret | hpr | |
|---|---|---|---|---|---|---|---|
| 305 | 10028 | 201107 | 7 | 2.0 | 5.0 | 0.247887 | 1.004524 |
| 306 | 10028 | 201108 | 8 | 3.0 | 5.0 | -0.032731 | 1.056241 |
| 307 | 10028 | 201109 | 9 | 4.0 | 5.0 | -0.054842 | 0.588236 |
| 308 | 10028 | 201110 | 10 | 5.0 | 5.0 | 0.029630 | 0.437932 |
| 309 | 10028 | 201111 | 11 | 6.0 | 5.0 | -0.070743 | 0.347828 |
| 310 | 10028 | 201112 | 12 | 7.0 | 5.0 | -0.036129 | 0.052114 |
| 311 | 10028 | 201201 | 13 | 8.0 | 5.0 | -0.026774 | -0.179457 |
| 312 | 10028 | 201202 | 14 | 9.0 | 5.0 | 0.081155 | -0.082847 |
| 313 | 10028 | 201203 | 15 | 10.0 | 5.0 | -0.048346 | -0.076543 |
| 314 | 10028 | 201211 | 23 | 11.0 | 12.0 | -0.246524 | -0.324221 |
| 315 | 10028 | 201212 | 24 | 12.0 | 12.0 | -0.036551 | -0.299355 |
temp2[['permno', 'yyyymm', 'midx', 'midx_lag', 'gap', 'ret', 'hpr']]
| permno | yyyymm | midx | midx_lag | gap | ret | hpr | |
|---|---|---|---|---|---|---|---|
| 305 | 10028 | 201107 | 7 | 2.0 | 5.0 | 0.247887 | 1.004524 |
| 306 | 10028 | 201108 | 8 | 3.0 | 5.0 | -0.032731 | 1.056241 |
| 307 | 10028 | 201109 | 9 | 4.0 | 5.0 | -0.054842 | 0.588236 |
| 308 | 10028 | 201110 | 10 | 5.0 | 5.0 | 0.029630 | 0.437932 |
| 309 | 10028 | 201111 | 11 | 6.0 | 5.0 | -0.070743 | 0.347828 |
| 310 | 10028 | 201112 | 12 | 7.0 | 5.0 | -0.036129 | 0.052114 |
| 311 | 10028 | 201201 | 13 | 8.0 | 5.0 | -0.026774 | -0.179457 |
| 312 | 10028 | 201202 | 14 | 9.0 | 5.0 | 0.081155 | -0.082847 |
| 313 | 10028 | 201203 | 15 | 10.0 | 5.0 | -0.048346 | -0.076543 |
| 314 | 10028 | 201211 | 23 | 11.0 | 12.0 | -0.246524 | NaN |
| 315 | 10028 | 201212 | 24 | 12.0 | 12.0 | -0.036551 | NaN |
Alternative way is to fill the gaps and assume the returns during the gaps are 0. This will keep more valid cumulative returns.
Summary statistics
crsp[['ret', 'lnme']].describe()
| ret | lnme | |
|---|---|---|
| count | 439721.000000 | 441959.000000 |
| mean | 0.011124 | 6.421212 |
| std | 0.177839 | 2.155586 |
| min | -0.993600 | -2.426619 |
| 25% | -0.058187 | 4.866619 |
| 50% | 0.004907 | 6.397188 |
| 75% | 0.066725 | 7.890045 |
| max | 19.883589 | 14.629090 |
# Percentiles
crsp[['ret', 'lnme']].describe(percentiles=[0.1, 0.9])
| ret | lnme | |
|---|---|---|
| count | 439721.000000 | 441959.000000 |
| mean | 0.011124 | 6.421212 |
| std | 0.177839 | 2.155586 |
| min | -0.993600 | -2.426619 |
| 10% | -0.140673 | 3.625798 |
| 50% | 0.004907 | 6.397188 |
| 90% | 0.152479 | 9.241648 |
| max | 19.883589 | 14.629090 |
# Summary statistics by year
crsp['year'] = crsp['date'].dt.year
round(crsp.groupby('year')[['ret', 'lnme']].describe()
.loc[:, (slice(None), ['mean', '50%', 'std'])], 4)
| ret | lnme | ret | lnme | ret | lnme | |
|---|---|---|---|---|---|---|
| mean | mean | 50% | 50% | std | std | |
| year | ||||||
| 2011 | -0.0064 | 6.0642 | -0.0089 | 6.0190 | 0.1486 | 2.0849 |
| 2012 | 0.0161 | 6.1141 | 0.0102 | 6.0783 | 0.1459 | 2.0934 |
| 2013 | 0.0325 | 6.3779 | 0.0228 | 6.3643 | 0.1331 | 2.0869 |
| 2014 | 0.0041 | 6.5273 | 0.0026 | 6.4729 | 0.1388 | 2.0568 |
| 2015 | -0.0048 | 6.4665 | -0.0062 | 6.4348 | 0.1783 | 2.1173 |
| 2016 | 0.0155 | 6.3939 | 0.0091 | 6.3736 | 0.1734 | 2.1637 |
| 2017 | 0.0134 | 6.5546 | 0.0066 | 6.5825 | 0.1531 | 2.1840 |
| 2018 | -0.0120 | 6.6320 | -0.0089 | 6.6748 | 0.1615 | 2.1934 |
| 2019 | 0.0197 | 6.5616 | 0.0137 | 6.5667 | 0.2078 | 2.2513 |
| 2020 | 0.0346 | 6.5497 | 0.0095 | 6.4663 | 0.2837 | 2.2452 |
# Summary statistics by stock exchange
round(crsp.groupby('exchcd')[['ret', 'lnme']].describe()
.loc[:, (slice(None), ['mean', '50%', 'std'])], 4)
| ret | lnme | ret | lnme | ret | lnme | |
|---|---|---|---|---|---|---|
| mean | mean | 50% | 50% | std | std | |
| exchcd | ||||||
| 1 | 0.0106 | 7.8429 | 0.0095 | 7.8152 | 0.1306 | 1.7410 |
| 2 | 0.0061 | 4.0257 | -0.0104 | 3.8878 | 0.2336 | 1.4255 |
| 3 | 0.0119 | 5.7896 | 0.0030 | 5.6982 | 0.1956 | 1.9301 |
# Summary statistics in subsamples
print('Before 2015')
print(crsp.query('year<=2015')[['ret', 'lnme']].describe())
print('\nAfter 2015')
print(crsp.query('year>=2016')[['ret', 'lnme']].describe())
Before 2015
ret lnme
count 223628.000000 224712.000000
mean 0.008081 6.308403
std 0.150606 2.096421
min -0.935356 -0.896832
25% -0.054922 4.771121
50% 0.004207 6.272747
75% 0.061369 7.744562
max 15.984456 13.528774
After 2015
ret lnme
count 216093.000000 217247.000000
mean 0.014274 6.537897
std 0.202149 2.209074
min -0.993600 -2.426619
25% -0.062021 4.975455
50% 0.005594 6.533329
75% 0.072987 8.032318
max 19.883589 14.629090
API reference: pandas.dataframe.describe
Stata¶
Import CRSP raw data
Import data from a url
local repo_url "https://raw.githubusercontent.com/mk0417/financial-database" local data_url "/master/data/crsp_demo.txt" local url = "`repo_url'" + "`data_url'" import delimited "`url'", clear
Import data from local directory
clear set more off cd "/Users/ml/Dropbox/teaching/data/" import delimited crsp_month_raw.txt, clear // list first five observations l permno date shrcd exchcd ret in 1/5
+------------------------------------------------+ | permno date shrcd exchcd ret | |------------------------------------------------| 1. | 10026 20201231 11 3 0.072598 | 2. | 10028 20201231 11 2 0.125541 | 3. | 10032 20201231 11 3 0.046848 | 4. | 10044 20201231 11 3 -0.051522 | 5. | 10051 20201231 11 1 -0.030851 | +------------------------------------------------+
Data dimension
// Number of observations
count
di _N
Data type
describe
Contains data
obs: 870,692
vars: 12
-------------------------------------------------------------------------------
storage display value
variable name type format label variable label
-------------------------------------------------------------------------------
permno long %12.0g PERMNO
date long %12.0g
shrcd byte %8.0g SHRCD
exchcd byte %8.0g EXCHCD
siccd str4 %9s SICCD
ncusip str8 %9s NCUSIP
permco long %12.0g PERMCO
cusip str8 %9s CUSIP
prc float %9.0g PRC
ret str9 %9s RET
shrout long %12.0g SHROUT
cfacpr float %9.0g CFACPR
-------------------------------------------------------------------------------
Sorted by:
Note: Dataset has changed since last saved.
// Convert date to date format
tostring date, replace
gen date1 = date(date, "YMD")
l permno date date1 ret in 1/5
+-------------------------------------------+
| permno date date1 ret |
|-------------------------------------------|
1. | 10001 20110131 31jan2011 0.028992 |
2. | 10001 20110228 28feb2011 0.022727 |
3. | 10001 20110331 31mar2011 0.072404 |
4. | 10001 20110429 29apr2011 -0.038789 |
5. | 10001 20110531 31may2011 0.028050 |
+-------------------------------------------+
// Convert ret to numerical
gen ret1 = real(ret)
drop ret
rename ret1 ret
// Convert siccd to numerical
gen siccd1 = real(siccd)
drop siccd
rename siccd1 siccd
describe
Contains data
obs: 870,692
vars: 13
-------------------------------------------------------------------------------
storage display value
variable name type format label variable label
-------------------------------------------------------------------------------
permno long %12.0g PERMNO
date str8 %9s
shrcd byte %8.0g SHRCD
exchcd byte %8.0g EXCHCD
ncusip str8 %9s NCUSIP
permco long %12.0g PERMCO
cusip str8 %9s CUSIP
prc float %9.0g PRC
shrout long %12.0g SHROUT
cfacpr float %9.0g CFACPR
date1 float %td
ret float %9.0g
siccd float %9.0g
-------------------------------------------------------------------------------
Sorted by:
Note: Dataset has changed since last saved.
Stock exchanges and common shares
// Keep NYSE/AMEX/NASDAQ
keep if inlist(exchcd, 1, 2, 3)
* Equivalently,
* keep if exchcd==1 | exchcd==2 | exchcd==3
// Keep common shares
keep if inlist(shrcd, 10, 11)
* Equivalently
* keep if shrcd==10 | shrcd==11
Drop duplicates
duplicates drop permno date, force
Save data
save crsp_month, replace
Read clean data
use crsp_month, clear
Generate new variables
// Market value
gen price = abs(prc)
gen me = (price*shrout) / 1000
gen lnme = ln(me)
// Adjusted price
gen adjprc = price / cfacpr
// Holding period return
gen yyyymm = mofd(date1)
format yyyymm %tm
gen logret = ln(1+ret)
sort permno yyyymm
forvalues i=1/5 {
by permno: gen l`i' = logret[_n-`i']
}
gen hpr = logret+l1+l2+l3+l4+l5
by permno: gen yyyymm_lag = yyyymm[_n-5]
format yyyymm_lag %tm
gen gap = yyyymm - yyyymm_lag
replace hpr = . if gap!=5
replace hpr = exp(hpr) - 1
Summary statistics
summ ret lnme
summ ret lnme, d
// Summary statistics by year
gen year = year(date1)
tabstat ret lnme, by(year) stat(mean p50 sd) long
tabstat ret lnme, by(year) stat(mean p50 sd) long nototal
tabstat ret lnme, by(year) stat(mean p50 sd) long nototal col(stat)
// Summary statistics by stock exchange
tabstat ret lnme, by(exchcd) stat(mean p50 sd) long nototal col(stat)
// Summary statistics in subsamples
summ ret lnme if year<=2015
summ ret lnme if year>2015